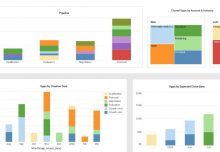
Here is something we’ve found frequently with our larger enterprise customers. They choose our software with a certain dashboarding project in mind driven by business need. They install our business intelligence platform on premise and create their pilot dashboard in a matter of hours.
As they prepare to roll it out and ask us about best practices, we find that their data environment and usage profile could lead to challenges. They have a data management problem that they hadn’t realized until they embarked on this project.
Fortunately our platform is perfectly suited to offer data management solutions. Not only does it include easy-to-use tools for designing interactive visualization dashboards and pixel-perfect reports, it has a very strong and flexible data access engine that can create an intermediate data layer that overcomes the performance challenges that these large enterprise customers inevitably will run into.
The types of scenarios that potentially call for using our intermediate data layer, which we call a data grid cache are when:
- The dashboard is mashing up data from multiple data stores.
- One or more of the data stores is an operational system that should not be made available for frequent ad hoc querying.
- The users are distributed globally and distant from the source systems.
- They are working with Big Data.
Scenarios 1 and 3 don’t necessarily require turning on our data grid cache option. Plenty of customers run their dashboards in the default live data access mode. But scenarios 2 and 4 will almost always will benefit from this caching option. And when their scenario also includes 1 or 3, then there’s all the more reason to use it.
The way the caching works is as follows. After you have designed your dashboard, you go into the admin utility and turn on the “materialized view” option for that specific dashboard. Our software intelligently analyzes the queries involved with that dashboard and creates a cache of all the data needed to support all of the interactive drill-down data needs. The technology design of the cache is based on MapReduce principles utilizing column-based indexing of the data.
The cache can reside in memory if enough is present, or it sits on disk, which still yields very high performance. It can be scheduled to be updated as frequently as desired, with just incremental updates, again, to optimize performance while being as close to real-time as needed.