Achieving Analytic Agility with Data Mashups
Executive Summary for the Report
Catalyst
The need to react quickly to a rapidly changing business climate is forcing organizations to make faster business decisions. But being able to quickly ask questions and get answers is not a simple task. While business intelligence (BI) tools and applications have emerged as viable solutions, traditional approaches to building and deploying these systems are complex, cumbersome, and expensive and often fail to keep pace with BI end-user demands and expectations. More often than not, resource-constrained IT departments are overburdened with BI requests, sometimes taking days, weeks, or months to fulfill them.
The challenge is to deliver a BI system that breaks the mold of traditional BI solution deployments by removing this IT bottleneck and shifting the analysis to business users. What's needed is a more agile approach that allows business users to self-service their BI needs. Ovum believes a key enabler for achieving self-service BI agility is data mashup technology.
Overview
Many BI systems continue to be designed by IT, based on rigid and inflexible data sources. This has created a bottleneck of end-user change requests as business needs constantly change and evolve. The inability of IT to keep up has given rise to "user-centric" system designs that provision business end user with self-service capabilities to satisfy their BI needs and provide relief to overstretched IT departments. This is not a new concept. Just as most motorists expect to pump their own gas without an attendant, corporate business end users increasingly want and expect the right information in their hands at the right time, without the intervention of IT.
BI vendors are making the jump to self-service in different ways. A promising way t o achieve self-service BI is an integration-oriented approach grounded in data mashup technology. Data mashups allow nontechnical business users to easily and quickly access, integrate, and display BI data from a variety of operational data sources, including those that are not integrated into the existing data warehouse, without having to understand the intricacies of the underlying data schemas.
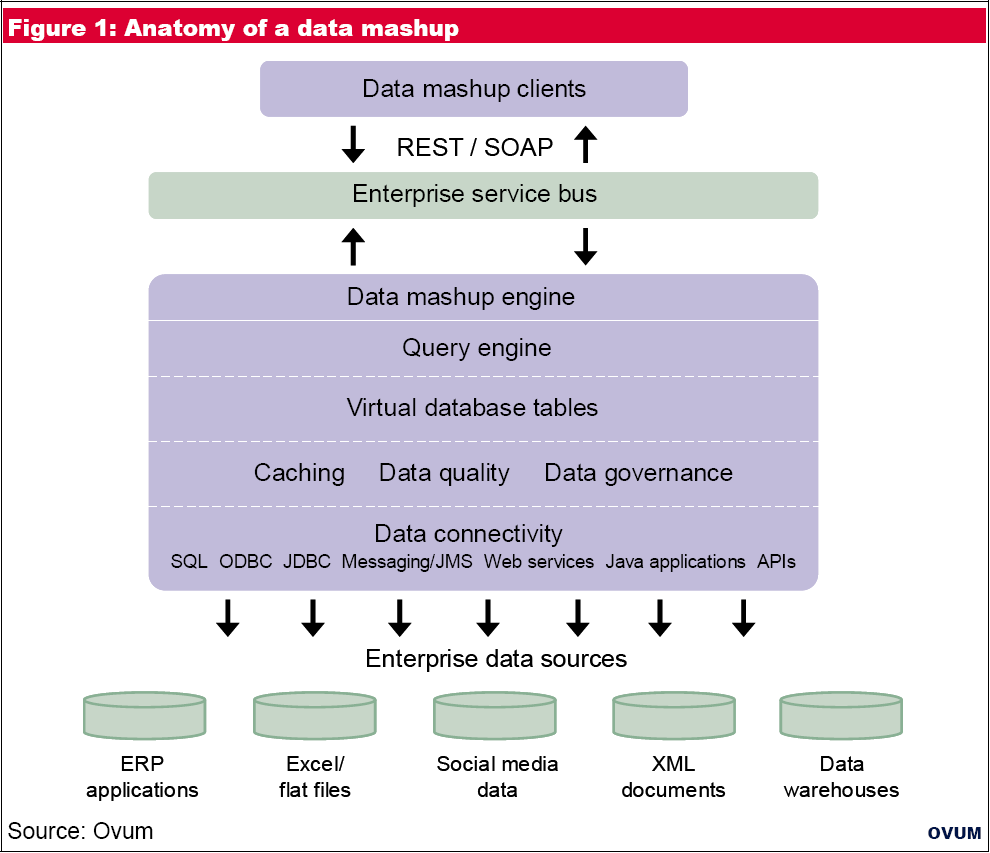
Anatomy of a Data Mashup
How Does Data Mashup Eliminate the Need for ETL Processes?
Data mashup is a technique used to integrate data from multiple sources or formats into a single dataset for analysis or visualization purposes. While data mashup can offer benefits in terms of agility and flexibility, it does not necessarily eliminate the need for Extract, Transform, Load (ETL) processes entirely. Instead, it complements traditional ETL processes and can be used in conjunction with them to streamline data integration workflows. Here's how data mashup and ETL processes compare and how they can work together:
- Data Mashup:
- Agile Integration: Data mashup allows users to quickly combine data from different sources or formats without the need for complex transformations or pre-defined schemas. It often involves using visual tools or self-service BI platforms to blend data interactively.
- Ad Hoc Analysis: Data mashup is well-suited for ad hoc analysis or exploratory data tasks where users need to combine and analyze data on-the-fly without formal ETL processes.
- User Empowerment: Data mashup empowers business users and analysts to perform data integration tasks without heavy reliance on IT or data engineering teams. It promotes self-service analytics and enables users to access and blend data as needed.
- ETL Processes:
- Structured Data Pipelines: ETL processes involve structured pipelines for extracting data from source systems, transforming it according to predefined business rules or requirements, and loading it into a target data warehouse or data lake.
- Data Quality and Governance: ETL processes often include data cleansing, normalization, deduplication, and validation steps to ensure data quality and consistency. They also enforce data governance policies and standards.
- Scalability and Performance: ETL processes are designed for handling large volumes of data efficiently and reliably. They can scale to process data from diverse sources and support complex transformation logic.
- Batch Processing: ETL processes typically operate in batch mode, scheduled at regular intervals to refresh data warehouses or update analytical datasets. They ensure that data is processed and available for analysis in a consistent and timely manner.
While data mashup can provide agility and flexibility for certain use cases, it may not be suitable for all scenarios, especially those involving large-scale data integration, complex transformations, or strict governance requirements. In many cases, organizations adopt a hybrid approach, leveraging both data mashup and ETL processes based on the specific needs of their use cases:
- Complementary Approach: Organizations use data mashup for ad hoc analysis, prototyping, or exploratory tasks where agility and self-service capabilities are essential. They rely on ETL processes for structured, governed data integration tasks that require scalability, reliability, and data quality assurance.
- Integrated Workflows: Data mashup tools and self-service BI platforms may integrate with ETL tools and data integration platforms to enable seamless workflows. For example, users can prototype data mashup scenarios using self-service tools and then operationalize them through automated ETL pipelines for production use.
- Data Governance and Control: Organizations establish policies and guidelines to govern the use of data mashup tools and self-service capabilities, ensuring that data integration tasks adhere to data quality, security, and compliance standards.

How an EV Manufacturer Saved Time and Money with InetSoft's Data Pipeline Solution
The DevOps team at an electric vehicle (EV) manufacturer faced mounting challenges as they managed their growing IT infrastructure. With traditional extract, transform, and load (ETL) processes, the team spent significant time and resources moving and processing data from various sources. As the EV industry rapidly advanced, the volume and complexity of data increased exponentially. Recognizing the inefficiency and cost of their existing system, the team sought a robust, scalable solution. Enter InetSoft's data pipeline BI (Business Intelligence) solution—a transformative tool designed to streamline data workflows.
By implementing InetSoft's solution, the team replaced their cumbersome ETL processes with an automated, real-time data integration system. InetSoft's pipelines allowed for seamless ingestion, transformation, and visualization of data without the need for manual interventions. The solution not only expedited data processing but also minimized errors associated with traditional methods. This modernization of data workflows became a cornerstone in the manufacturer's strategy to optimize operations and drive cost efficiency.
One of the most significant benefits was the reduction in IT operational costs. The old ETL framework required dedicated servers, significant storage, and maintenance efforts. InetSoft's BI solution leveraged a more lightweight and agile infrastructure. By migrating to this streamlined system, the manufacturer significantly reduced expenditures on hardware, software, and maintenance contracts. This shift represented an immediate win for the DevOps team, aligning with the company's sustainability goals.
Moreover, the InetSoft solution dramatically reduced man-hours spent on data management. The DevOps team previously allocated substantial time to troubleshooting, manual data cleansing, and ensuring system compatibility. With a highly intuitive and automated data pipeline, much of this manual effort became obsolete. Instead of being bogged down by repetitive tasks, team members could redirect their expertise toward innovative projects that directly supported the company's core mission of accelerating EV adoption.
Another key advantage was the enhanced visibility into operations. InetSoft's BI tools provided real-time dashboards and analytics that offered a comprehensive view of the entire supply chain, production processes, and market trends. Armed with actionable insights, decision-makers could quickly identify inefficiencies and optimize resource allocation. This newfound agility allowed the company to respond more effectively to market demands and strengthen its competitive position.
The adaptability of InetSoft's solution also played a critical role. As the EV manufacturer expanded operations into new markets and introduced additional vehicle models, the data pipeline BI system easily scaled to accommodate new data sources and integration needs. The DevOps team no longer had to worry about the rigidity of outdated ETL systems and instead relied on a future-proof solution that could grow with the company's ambitions.
Furthermore, the InetSoft implementation fostered a culture of innovation and collaboration across departments. Teams from manufacturing, marketing, and customer service could access accurate, up-to-date data tailored to their specific needs. The improved data transparency and accessibility encouraged cross-functional synergies, ensuring that everyone worked toward shared organizational goals.
The financial savings and efficiency gains also allowed the EV manufacturer to reinvest in other critical areas, such as research and development for next-generation batteries and autonomous driving technology. The DevOps team took pride in knowing their efforts had not only improved IT operations but also contributed to the broader mission of creating more sustainable transportation solutions.
In summary, the adoption of InetSoft's data pipeline BI solution revolutionized the DevOps team's approach to data management at the EV manufacturer. By eliminating outdated ETL processes, the team saved both IT budget and man-hours, freeing up resources for innovation and growth. This strategic move not only streamlined operations but also empowered the company to focus on its vision for a greener future, underscoring the transformative power of modern BI solutions in today's data-driven world.