What is a Database Schema?
A database schema is the table structure of a database, independent of the data it contains. Database theory offers a mathematical description of database schemas, but from a practical perspective a schema specifies the table names, number of columns in each table, column names, and data types. The schema fully specifies the scope of data that can be read or written to the database, but does not include any data. The schema also specifies that certain columns are special 'key' columns for purposes of relating data.
For example, the SALES_EMPLOYEES table below has a primary key column called EMPLOYEE_ID. This is the unique employee identifier.

When this column appears within other tables, such as ORDERS, it is called a foreign key. A foreign key is simply a primary key from a different table.

The key columns allow a set of tables to be related so that data can be retrieved from multiple tables in a consistent fashion. Even though the employee name and order information reside in different tables, a consistent set of records can be retrieved by using the key columns to relate the data.
Databases provide query languages such as SQL that allow data to be retrieved in sophisticated ways from multiple tables by specifying relationships called joins that can relate data in ways that go beyond basic key relationships. The details of such query languages are outside the scope of this discussion, so let's continue to some other issues related database schemas.
A major issue in the design of database schemas is efficiency, relating to the amount of space consumed by data in the given table structure as well as the speed with which it can be retrieved. Database schemas are designed around so-called normal forms. The purpose of these normal forms is to store data with minimal redundancy. The process of converting a flat data set into a normal form is called normalization. The reverse process, converting data from a normal form into human-readable flat form, is called denormalization.
Without going into great detail, it is still easy to see the benefits of normalization and reduction of redundancy. Consider the flat data set below. This is what you might find in an Excel Spreadsheet.
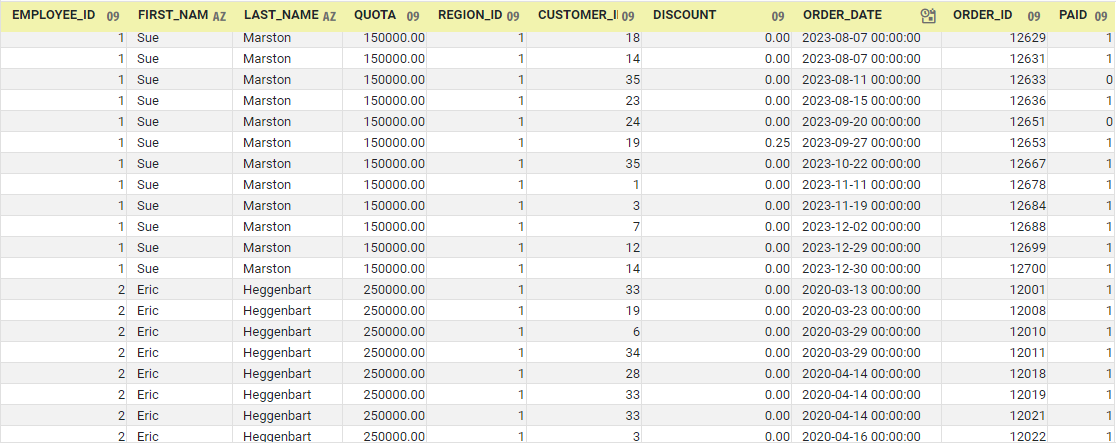
This data set clearly contains tremendous redundancy; for example, the salesperson's first name, last name, ID, etc., are always the same in every row. There is no need to repeat them for every item in every order. This is just a waste of space. Clearly this information should be factored out and stored separately. But this is not only a matter of efficiency; it is also necessary to maintain data integrity. If the data were stored as shown above, the data could easily become corrupted by someone, for example, mistyping a salesperson's last name when entering some of the orders. Over time, errors could propagate throughout the data set and eventually necessitate tedious data cleaning.
Efficiency and data integrity is much better served by storing the salesperson information separately, as below. This dramatically reduces redundancy and storage requirements, and also cuts down on the number of entry points where errors can be inserted into the data.

As mentioned earlier, when the time comes to obtain a larger data set such as the 10-column data set shown above, tables can be joined together using key columns or other constraints in order to assemble the desired data.
The disadvantage of database normal forms is of course that they tend not to be easily human-readable. If data is scattered across dozens or hundreds of tables, then automation will be required to assemble any data set that is meaningful to human users. For the data to be understandable to a business user, queries must be executed on the database to assemble the data into a flat or denormalized result set, similar to an Excel data set, one that users can easily comprehend.
There are, however, other structures in which data can be represented that are neither the strict normal forms of the traditional database, nor the simplified flat format of a spreadsheet. One of these other models is the so-called "entity-attribute" model. The next section discusses the implementation of this model with InetSoft.
Entity-Attribute Models for Business Use
An entity-attribute model, such as the Data Model provided by InetSoft, is designed to make the data stored in a database schema accessible to business users. As mentioned earlier, databases use certain normal forms for efficiency and integrity, but these normal forms make the data essentially inaccessible to human users. On the other hand, denormalizing the entire database into spreadsheet form would be technically impractical and would result in a spreadsheet of overwhelming size, which would be equally useless to business users. Therefore, traditionally, business users have had to commission database administrators to create queries that could retrieve the desired data sets from company databases, and this administrative overhead might create a bottleneck in accessing and understanding critical business data.
Entity-attribute models present an intermediate approach by creating an abstraction of the database. This is a layer that maps fields from database tables to attributes that reside within entities. For example, the Order Model here (partially expanded to show attributes) contains entities called Customer, Order, Product, Salesperson, and Supplier. Each of these entities contains related attributes. For example, the Salesperson entity contains First Name, Last Name, Quota, and Region.
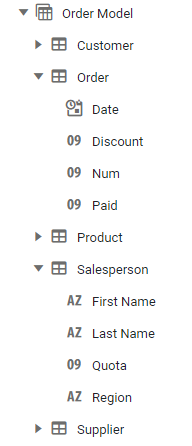
The idea behind this abstraction is that a business user can understand what all of the fields are, and how they relate to each other. The user can choose the particular combination of attributes for which they want to see data, and the corresponding flat data set will then be assembled for just those selected fields. This makes the data accessible and manageable by the business user. At the same time, queries to retrieve the requested data set from the database can be automatically constructed on the fly so that database administrators do not need to have ongoing involvement in business research and reporting. Once the model has been created, business users can access data it independently without intervention from IT staff.
From a technical standpoint, the entity-attribute model preserves all of the benefits of database storage, because the data remains in the database (in efficient normal form) until it is needed. Further efficiencies are achieved by caching data sets with recurrent usage to avoid unnecessary querying of the database, and InetSoft additionally adds many features to make data models even more powerful, such as data typing, automated hyperlinks and drill-downs, default aggregations and formatting, and so on.