Supercharging BI with Spark, Easy Machine Learning with InetSoft
A Little Bit of History
Even since the creation of the Apache Hadoop project more than 10 years ago, many attempts have been made to adapt it for data visualization and analysis. The original Hadoop project consisted of two main components, the MapReduce computation framework and the HDFS distributed file system.
Other projects based on the Hadoop platform soon followed. The most notable was Apache Hive which added a relational database-like layer on Hadoop. Together with a JDBC driver, it had the potential to turn Hadoop into a Big Data solution for data analysis applications.
Unfortunately, MapReduce was designed as a batch system, where communication between cluster nodes was based on files, job scheduling was geared towards batch jobs, and latency of up to a few minutes is quite acceptable. Since Hive used MapReduce as the query execution layer, it was not a viable solution for interactive analytics, where sub-second response time is required.

This didn't change until Apache Spark came along. Instead of using the traditional MapReduce, Spark introduced a new real-time distributed computing framework. Furthermore, it performs executions in-memory so job latency is much reduced. In the same timeframe, a few similar projects have emerged under the Apache Hadoop umbrella such as Tez, Flink, and Apex. Finally, interactive analysis of Big Data was within reach.
Current State of Art
As Spark quickly gained the status of the leading real-time cluster framework, it has attracted much attention in the BI community. By now, almost every BI vendor has some kind of story about integrating their products with Spark.
The most common integration is to treat Spark as a new data source. A BI tool could be connected to a Spark/Hadoop cluster through a JDBC/ODBC driver. Since Spark SQL provides an SQL-like language, it could be treated as a traditional relational database. This approach is simple and easy to accomplish, so it is normally the first option when a BI tool integrates with Spark.
Some tools tried to go further. One option is to use Spark as a replacement for ETL. Instead of the traditional ETL pipeline, data could be ingested into a Hadoop cluster, and Spark is used to transform and process the raw data. The result is saved into another data store to be consumed by the BI tool.
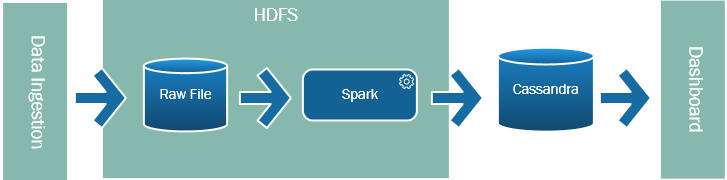
Native Spark Integration
Using Spark in various roles outlined above has its value, and Spark will continue to be an important part of the overall BI pipeline. However, keeping Spark outside of the BI tool fails to take full advantage of the power of Spark in many ways.
First, having Spark as an external system means data needs to be moved from a Spark cluster to the BI tool. In the age where software is actively engineered to reduce data movement even between RAM and CPU cache, moving data between machines or processes can be disastrous to performance.
Secondly, treating Spark simply as a database, or even as a preprocessor of data, robs a BI tool of the opportunity to fully utilize the computing power of a cluster. Imagine when you need to join data from Spark and a simple in-memory reference table. Since the in-memory table is not part of the Spark cluster, the BI tool needs to execute a query against Spark, bring the data out of the cluster and into the BI tool, and then perform a join in the BI tool.
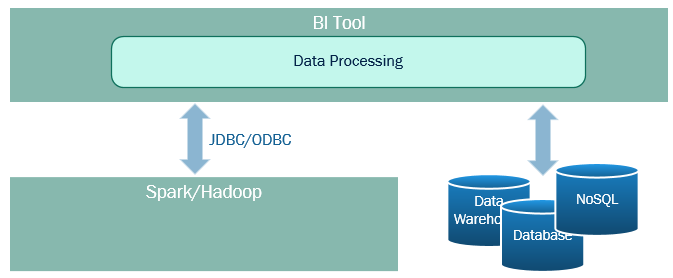
This example illustrates the two main disadvantages of keeping a BI tool separate from Spark. First, potentially large amounts of data may need to be moved between systems. Additionally, joining of the data cannot be performed inside the cluster. This may result in the cluster being idle while a single BI server is consumed with performing the actual data processing.
More Articles About Deployment
-
Connect And Blend Apache Spark Data
This article explains how the platform enables connection to Apache Spark data and other large-scale sources, making data usable and understandable. It highlights that rather than moving Big Data out of Spark, the platform can work directly against Spark and use in-memory caching to accelerate queries. It discusses how this approach avoids slow response times typical in large datasets and supports interactive dashboards. The article emphasises that the tool supports multiple disparate data sources, allowing mashup with Spark and traditional systems.
-
Optimize Spark For Interactive Analytics
This piece explores how the BI application integrates natively with Spark and uses specialized logic to push query processing down into the storage layer and optimise performance. It details three methods of acceleration: candidate query materialization, push-down logic to storage, and a specialized columnar data store compatible with Spark APIs. It also explains that Spark’s capabilities like ML and streaming are considered core to this integration. The article positions Spark as more than just big data processing, but a platform for interactive visual analytics when paired with the right BI layer.
-
Enhance Spark Job Deployment With Orchestration
This article compares pure Spark clustering with orchestration engines, explaining that while Spark is effective, orchestration adds broader deployment, scheduling, dependency and self-healing management. It highlights advanced features such as CI/CD integration, multi-tenant isolation, and granular permissions for Spark job workloads. The piece emphasises how orchestration enables better resource efficiency, scalability and reliability across Spark clusters. It suggests that organisations planning to deploy Spark-based BI should consider orchestration engines as part of the deployment architecture.
-
Deploy A Small-Footprint Analytic Platform
This article describes how the analytic tool uses a web-based architecture and minimal client install to facilitate fast deployment. It explains that the platform supports multiple data source connections, intuitive drag-and-drop, and scales from small to enterprise deployments. The piece emphasises flexibility and integration capability, enabling deployment in different environments including cloud and on-premises. It also stresses how such a platform simplifies rollout and adoption across business users, IT and developers alike.
-
Accelerate Business Intelligence Server Roll-out
This article presents how the BI server can be installed quickly via a setup wizard with minimal configuration, enabling rapid deployment across existing systems. It emphasises the cloud-based, platform-neutral architecture that supports fast set-up and ongoing maintenance with automated updates. The text highlights that the deployment process is designed for teams with limited technical resources and reduces the barrier to adoption. It also mentions that the solution supports growing data demands and evolving needs without frequent manual adjustment.
-
Install Platform-Independent BI Runtime Libraries
This technical article explains the deployment process of including the appropriate JAR files for the runtime and describes how the BI software is fully platform-independent and written in Java. It includes guidance on which JARs to include depending on edition and environment, and explains the architecture including MVC, adapters and design patterns. The piece is especially relevant for Java developers preparing the production deployment environment. It also highlights that the server environment is designed to allow minimal installation effort and flexible configuration.
-
Deploy Analytics Inside Hadoop/Spark Cluster
This article covers how the analytics engine can execute natively within a Hadoop or Spark Big Data OS rather than retrieving data outside the environment. It emphasizes the “bring-the-engine-to-the-data” approach which avoids the cost and complexity of bulk data movement. It also details how self-service visual analysis and mashup can occur inside the Big Data environment for better performance and scalability. The article suggests that deploying inside Hadoop/Spark is more efficient than traditional BI architectures for massive data volumes.
-
Launch Open-Source Container Deployment
This article describes the open-source container packaging of the BI platform built as a Docker container that supports compact deployment via Docker Desktop or in the cloud. It emphasises that users can start with a basic instance and scale as needed, with minimal setup required. It highlights the flexibility of container-based deployment and support for cloud environments. The piece positions container deployment as a modern, efficient route to bring analytics into production quickly.
-
Enable Live Deployment From Designer
This how-to article explains how developers can deploy reports directly from the designer tool by enabling the ‘Live Deployment’ option in the Enterprise Manager on the server. It gives step-by-step instructions: launch the Enterprise Manager, navigate to Deployment settings, enable live deploy, then deploy a report via the designer by specifying server URL and folder. It highlights how this capability accelerates the process of getting dashboards into the portal without full administrator involvement. The piece positions live deployment as a key feature for agile BI rollout in production environments.
-
Create Deployment WAR Files For Web Servers
This article focuses on the process of creating a WAR archive via the Deployment Wizard to package servlets, repository, portlet, SOAP modules and all replet jars for application server deployment (Tomcat, WebLogic, WebSphere). It gives specific steps for selecting application server options, naming the archive file, and including extra resource files, portlets and SOAP bundles. It emphasises that once the archive is created it can be deployed on any compliant J2EE application server, simplifying production rollout. The article underscores the importance of packaging and deployment artifacts for enterprise-grade BI environments.
