Integrating Spark into the BI Application - The InetSoft Approach
To avoid the aforementioned problems, the key is to break down the barrier between Spark and the BI tool. Instead of relying on the JDBC/ODBC interface, we completely fused Spark into StyleBI. The following is a high-level view of the integration.
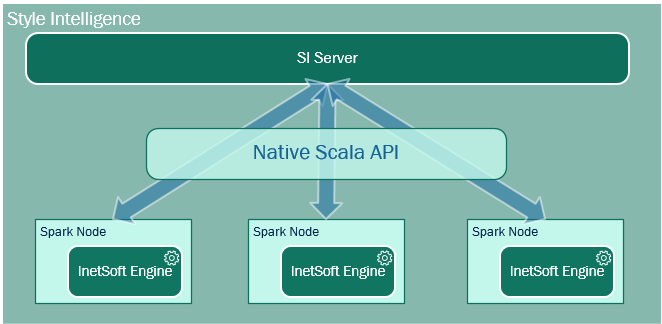
All interactions between StyleBI and Spark are through the native API. Spark becomes a native part of the product. Data inside a cluster can be accessed through Spark SQL using SQL-like queries, or directly as files or data connectors provided by the data stores. Unlike JDBC, data is not retrieved from Spark until it has finished all processing and is ready to be presented to users.
Equally importantly, data processing jobs normally performed by BI tools are also pushed into the cluster. For example, to join the result of a Spark SQL query with an in-memory table, the in-memory table is pushed into the cluster, and the join is submitted to the InetSoft execution engine embedded in the Spark nodes. Data already residing in the cluster is never moved.

Analytic Query Acceleration
Spark is a general purpose computing platform. Although it was designed to handle real-time computing needs, it provides no special treatment for analytic queries. A BI tool could use Spark as-is and get decent performance. But BI queries generated by interactive analysis often have distinct patterns, and it is possible to use this knowledge to further optimize the execution. As a natively integrated tool, Style Intelligence is in a unique position to add special logic to improve performance further. The acceleration is achieved by three methods:
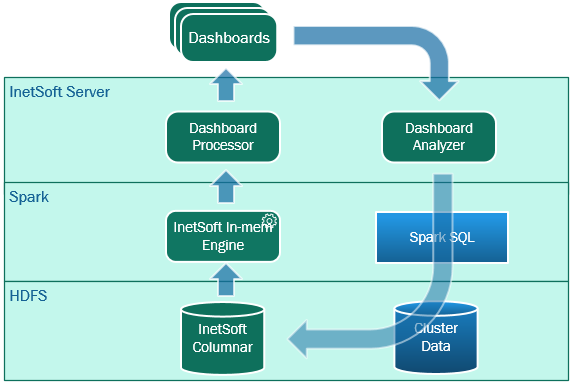
- StyleBI analyzes a visualization and generates candidate queries to materialize. The goal is to preprocess as much as possible and only leave the parts that need to be dynamically updated to be performed later.
- For data stored in a materialized format, logic responsible for handling interactive queries is pushed down to the data storage layer whenever possible. This significantly reduces the amount of data Spark needs to process.
- A specialized columnar data store is created to store the materialized data. It conforms to the standard Hadoop/Spark API so it can be accessed by Spark jobs, but is optimized to handle the types of queries generated from interactive analysis.
Spark Is More Than Big Data
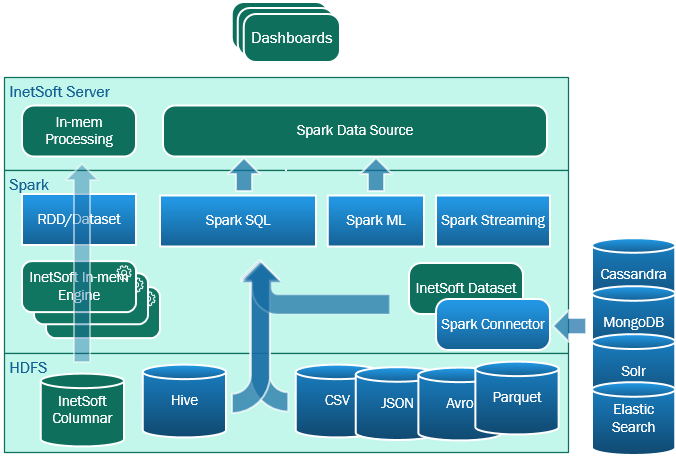
While Spark gained its fame through its real-time cluster computing platform, it comprises many other components. Many of those are of great interest to BI users. Ignoring them would be a great disservice to users. Chief among them are Machine Learning (Spark ML) and streaming. We consider both areas as core capacities of any future BI tool and have brought them into the product as part of the native integration with Spark.

Spark ML
Spark ML provides an opportunity to bring Machine Learning to the masses, and we view StyleBI as the bridge from Spark ML to business users. The integration has the following objectives:
- Creating and training models should be easy and accessible to people with minimum Machine Learning training. Every opportunity was taken to automate the process.
- Once a model is trained, it should be available to business users with no Machine Learning knowledge.
- Like Spark queries, Spark ML integration is done at the native level, fully integrated into the product, so it enjoys all the benefits of the cluster.
Spark ML provides built-in algorithms in the following areas:
- Classification - prediction of categorical values
- Regression - prediction of numeric values
- Clustering - automatic grouping of similar items
- Recommendation
The first three are available in StyleBI and can be accessed as a regular query without any programming or special knowledge.

Spark ML
Streaming is another area that is revolutionizing BI applications. Not long ago, real-time data processing was considered a niche requirement and often reserved for the most specialized applications. With the advent of Kafka and Spark, streaming has been brought into the mainstream.
However, many challenges remain. Compared with batch processing, streaming needs to deal with many new problems such as back pressure and late arriving records. In addition, programming is often required to create a streaming application.
Spark Streaming provides an abstraction of stream processing that nicely fits into the overall Spark framework. We are actively working on integrating streaming into StyleBI. The goal is to simplify stream processing and make it accessible to regular users without programming skills. To a large degree, building a query against a stream should not be much different from a query against a database.

Summary
Big Data is more than throwing a cluster together and connecting to it through a JDBC driver. It requires an architecture that has all the pieces working closely together. It's our view that the most effective solution requires a complete fusion of the various technologies.
The StyleBI/Spark integration is the first step in achieving this vision. As the innovations flourish, our mission is to create a platform that effortlessly integrates with software in the Hadoop ecosystem, so business users can enjoy all the benefits.
Related Resources About Spark
-
Data Grid Caching Technology
Explains how InetSoft connects to large-scale Spark sources and uses an in-memory data grid cache to avoid repeatedly scanning huge datasets, improving dashboard responsiveness. Describes use cases where Spark-held data can be queried and blended with other enterprise sources without moving the original data. Highlights the performance benefits of caching compressed, analytic-ready data blocks for interactive visual exploration. Recommends InetSoft’s approach for organizations that need real-time style dashboards over very large Spark datasets.
-
Pushed Into The Cluster
Describes how InetSoft’s BI engine integrates natively with Spark so that analytic processing can be executed directly inside the cluster rather than extracting raw data out. Explains that in-memory tables can be pushed into the cluster and join operations executed there to preserve performance and avoid unnecessary data movement. Notes that Spark SQL and direct file connectors are supported so clusters appear as first-class analytic sources. Emphasizes the practical benefits for hybrid workloads where some transforms are best done on-cluster.
-
Traditional Relational Database
Frames Spark as a queryable data source that can, for BI purposes, be treated like a relational backend using Spark SQL and standard drivers. Discusses alternate integration strategies—connecting via JDBC/ODBC, or embedding analytic jobs into the cluster so the BI tool leverages cluster compute. Covers how Spark can replace or augment ETL by performing heavy transformations natively before BI consumption. Suggests this model simplifies handling streaming and batch data while enabling easy adoption by BI teams.
-
Mash Up Such Sources
Outlines InetSoft’s claim that its analytic engine can run natively inside Hadoop/Spark environments, allowing mashups and visual analytics to execute with full cluster power. Explains the ability to combine enterprise data from relational stores, APIs, and NoSQL with on-cluster assets without copying large volumes of data. Describes the “Big-Data-In-A-Box” option for teams that want an easy, Docker-packaged Spark-enabled deployment to avoid Big Data ops complexity. Conveys that the approach shortens time-to-value for organizations lacking deep Big Data expertise.
-
Analytic Query Acceleration
The whitepaper details how InetSoft leverages Spark to accelerate analytic query processing and scale visual analytics workloads. Covers techniques for pushing computation into the cluster, using Spark SQL, and minimizing data movement to preserve throughput and latency SLAs. Includes architectural recommendations for combining in-memory BI acceleration with Spark compute for large volumes. Offers concrete examples of performance gains and deployment patterns for enterprise BI teams.
-
High Performance And Acceleration
Describes StyleBI’s mashup engine and how it achieves high performance, including integration points with Spark for scalable processing. Explains the concept of analytic-ready data blocks and optional compressed cache blocks that deliver faster interactive performance over big datasets. Notes that combining InetSoft’s engine with Spark cluster scalability often yields substantial speedups compared with naive direct queries. Positions the product as suitable for organizations that need both self-service analytics and Big Data scale.
-
Built-In Dedicated Spark
Highlights InetSoft’s easy path to big data analytics, including an option to deploy a built-in dedicated Spark/Hadoop cluster for customers that do not yet have cluster infrastructure. Explains how the platform can either attach to existing clusters or provide pre-packaged cluster nodes (Big-Data-In-A-Box) for rapid deployment. Describes on-the-fly data transformation and mashup capabilities that allow analysts to combine diverse sources into a unified analytic environment. Advises this route for teams seeking a cloud-ready, scalable BI solution with minimal Big Data operational overhead.