Evaluate InetSoft's Native Big Data Analytics Application
Introduction
Hadoop/Spark has emerged as an open standard Big Data Operating System with wide community support. It allows the usage of in-cloud or on-premise commodity hardware to effectively address the "3 V's" of Big Data: volume, variety and velocity.
Moreover, it brings a new generation of intelligent functions as standard components including machine learning, real-time streaming and graphical analysis. This combination makes it an ideal operating system for data processing.
Data Operating Systems, like regular operating systems, provide powerful base functions. These functions are essential for programmers, but business users can only benefit from them through applications created by programmers.
This is analogous to how business users need an app like Microsoft Office to benefit from Microsoft Windows. InetSoft's data intelligence app is the application for data analytics, visualization, dashboards, and reporting that's specifically designed for this Big Data Operating System.


Don't Many Analytic Tools Work with Hadoop?
The answer is a little bit of 'yes' and a big bit of 'no.' Hadoop, recognized as a de facto standard, enjoys widespread analytic tool support. That is the small bit of 'yes.'
The big bit of 'no' is that traditional tools just "connect" to Hadoop. To these tools, Hadoop is just another data store or database to get data from. Besides this data link, these tools reside and execute in a totally different environment. This vastly limits how much the tools can utilize the Big Data OS. The PC analogy is how non-Windows software can connect to Windows to access files stored on it, yet it is not an application running on Windows.
InetSoft's App Is a Native Big Data OS Analytic Engine
InetSoft's analytic engine natively executes on and inside Hadoop/Spark Big Data OS. It takes advantage of Hadoop/Spark's power to the fullest extent. Instead of retrieving data out of the Hadoop environment in order to process it, InetSoft brings the engine into the Big Data OS. This allows the analytic engine's mash up, visual analytics, data instructions, machine learning processing, and many others functions to execute with the full power of Hadoop.
Beyond the native engine, InetSoft also brings data into the Big Data OS. Enterprise data, from traditional databases, data warehouses, API-accessed data, and NoSQL data, can all be dynamically brought into the Big Data OS as analytics demand. A data lake, with little or no design for any particular purpose, normally resides inside a Big Data platform. InetSoft's analytic engine can tap into and mash up such sources without any data movement.
A Small Learning Curve, Big-Data-In-A-Box
InetSoft's analytic engine is designed for easy and gradual learning and scaling. As a first step, it can even be deployed without Hadoop/Spark. Even though this limits accessibility to advanced Big Data functions, it offers good analytic dashboarding and reporting.
Big-Data-In-A-Box is InetSoft's answer to the complexity of the Big Data OS. Install InetSoft's pre-packaged Hadoop/Spark Docker Container on each cluster node, and InetSoft's visualization server manages the environment.
No more Big Data technology knowledge is required. This means organizations with no Big Data experts can deploy the InetSoft Big Data solution. Visual analytics and reporting will automatically take advantage of the Big Data OS.
For organizations with more mature Big Data implementations, the InetSoft engine can be dropped into an existing Hadoop/Spark installation. Existing data, machine learning models and other assets will all become available to users for visual analysis and mashup. Data scientists, developers and business users can seamlessly cooperate on a single Big Data platform.
How A Holographic Display Manufacturer Uses StyleBI for Big Data Analytics
The market for holographic displays is highly specialized, driven by innovations in optics, electronics, and software that enable three-dimensional visual experiences across industries such as entertainment, education, healthcare, and retail. A Holographic Display Manufacturer faces complex operational and strategic challenges, including monitoring production quality, optimizing R&D processes, forecasting demand, and understanding customer preferences for highly customized products. To meet these challenges, the company adopted InetSoft’s open-source StyleBI platform for big data analytics, enabling a comprehensive, real-time view of operations and performance metrics. StyleBI provides advanced analytics, interactive dashboards, and predictive capabilities that help the manufacturer leverage its extensive datasets for actionable insights.
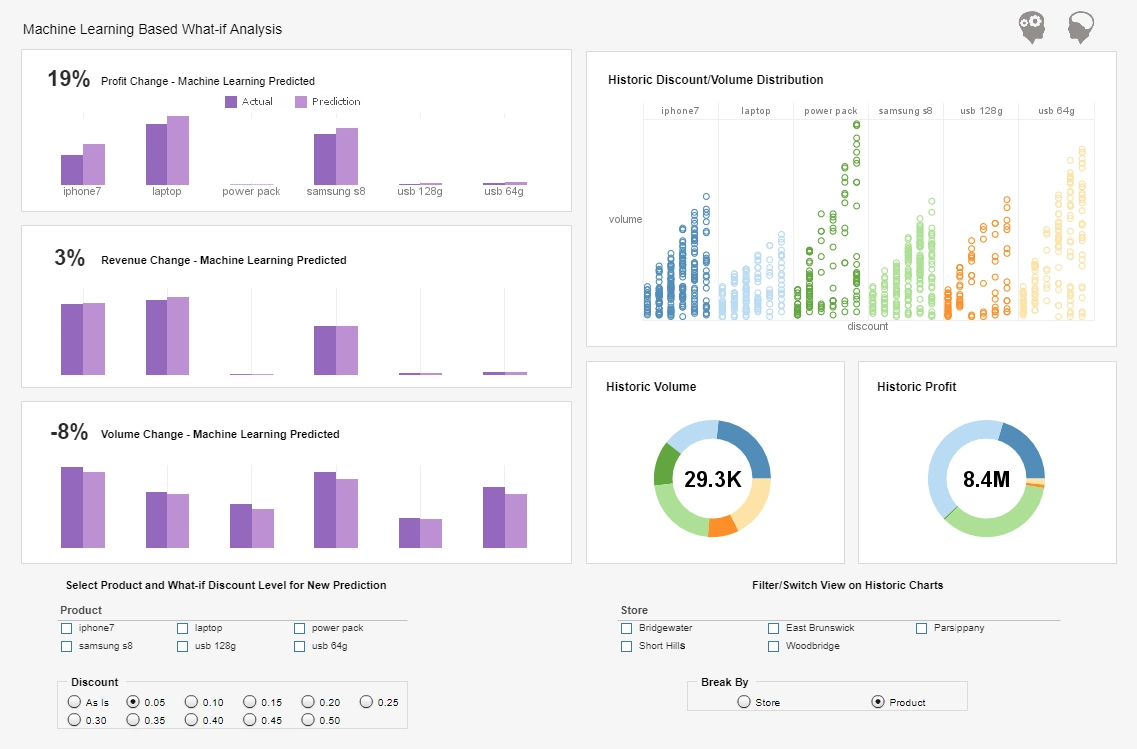
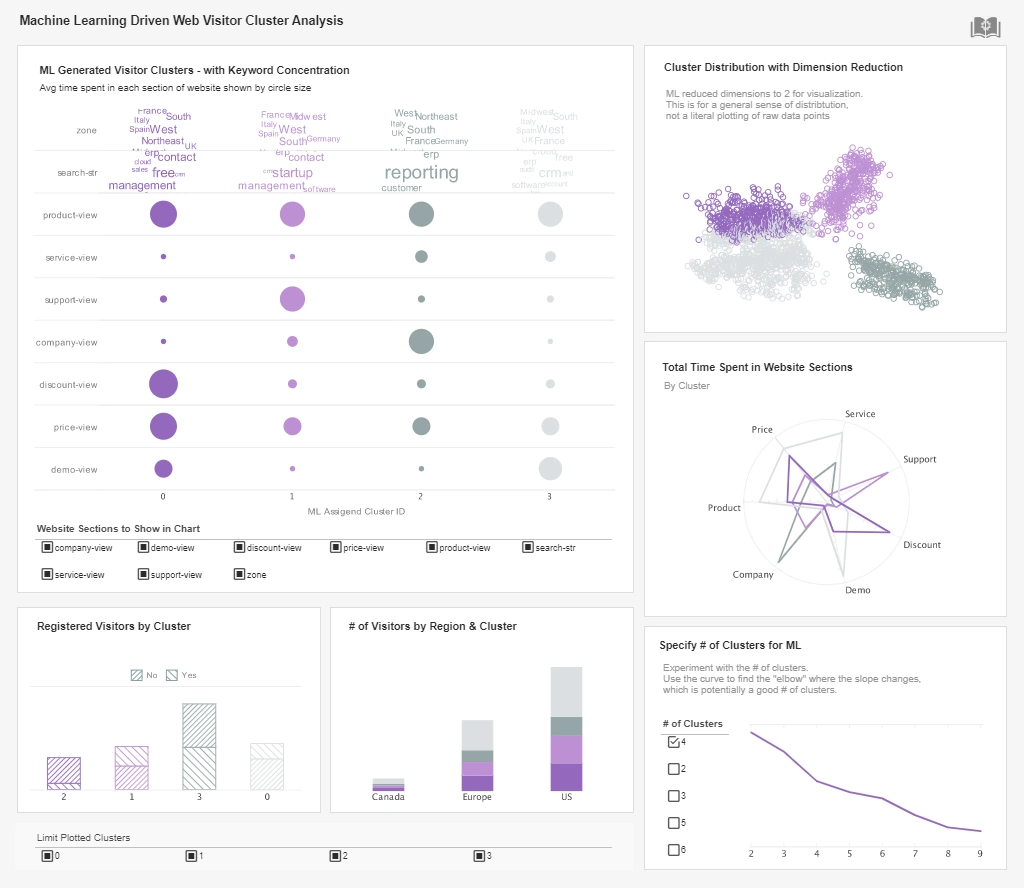
One of the primary applications of StyleBI within the company is production monitoring. Holographic displays require precise manufacturing processes that integrate optics, electronics, and software. StyleBI dashboards consolidate data from production machines, quality inspection systems, and supply chain logs. KPI tiles display metrics such as defect rates, yield percentages, assembly line throughput, and component lead times. Line charts track production trends over time, highlighting any deviations from targets, while heat maps can identify recurring defects or bottlenecks in specific assembly stations. These dashboards enable manufacturing engineers and managers to detect issues proactively, reduce downtime, and maintain high-quality output.
Research and development is another area where StyleBI provides valuable analytics. The company’s R&D teams generate data from prototype tests, simulation software, and performance measurements of display units. Dashboards aggregate test results across multiple iterations, allowing engineers to identify which design changes yield measurable improvements in display brightness, contrast, or color fidelity. StyleBI’s interactive charts enable drill-down analysis by prototype version, test environment, or device type, helping teams isolate factors contributing to success or failure. Predictive analytics models also simulate the likely impact of design modifications on production feasibility and cost, enabling more informed decision-making in product development.
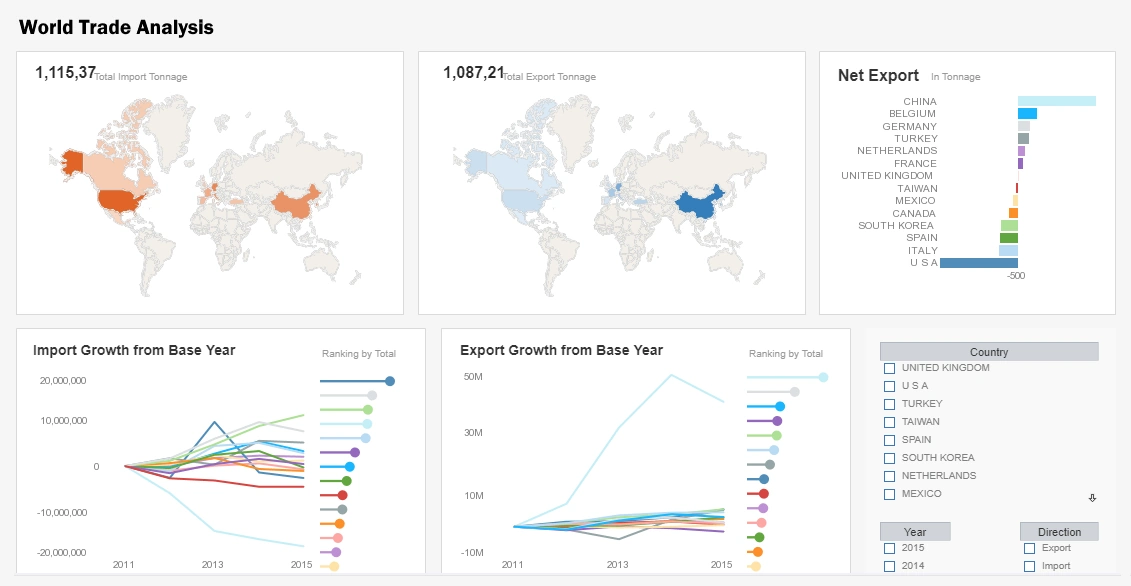
Supply chain optimization is crucial for a company that relies on specialized components such as lasers, optical materials, and electronic circuitry. StyleBI dashboards track inventory levels, supplier performance, and delivery times in real time. KPI tiles show supplier lead times, order fulfillment rates, and component cost variances, while time-series charts visualize trends in procurement and stock availability. When a critical component faces delays, the dashboard can simulate the impact on production schedules, allowing managers to adjust orders or prioritize alternative suppliers. This integration of big data analytics into supply chain management helps ensure production continuity and cost efficiency.
Sales and marketing analytics are central to understanding market demand for holographic displays, which vary widely depending on the application. StyleBI dashboards combine data from e-commerce platforms, distributor sales records, customer inquiries, and industry reports. Interactive charts display sales by region, product type, or industry segment, and allow filtering by customer demographics or purchase patterns. KPIs such as average order value, repeat purchase rates, and lead-to-sale conversion rates are tracked continuously. Using these insights, the marketing team can identify high-potential segments, refine promotional strategies, and optimize pricing models for different market niches.
Customer feedback and support data also feed into StyleBI dashboards, providing a holistic view of product performance and user satisfaction. The company aggregates product return data, support tickets, and online reviews to track recurring issues or feature requests. Sentiment analysis visualizations help identify patterns in customer feedback, while funnel charts illustrate how efficiently support requests are resolved. This information is crucial for guiding product improvements, training support staff, and enhancing overall customer experience. By integrating feedback into a centralized analytics platform, the manufacturer can respond quickly to market demands and maintain a competitive edge.
Financial performance is closely monitored through StyleBI’s big data analytics capabilities. By linking ERP systems, accounting software, and production cost databases, the company creates comprehensive financial dashboards. KPIs such as gross margin per product line, cost per unit, return on R&D investment, and operating expenses are displayed using KPI tiles, bar charts, and trend lines. These dashboards allow executives to track profitability across product types and geographies, identify underperforming segments, and make strategic budgeting decisions. Predictive models simulate the financial impact of production adjustments, new product launches, or marketing campaigns, enhancing the precision of financial planning.
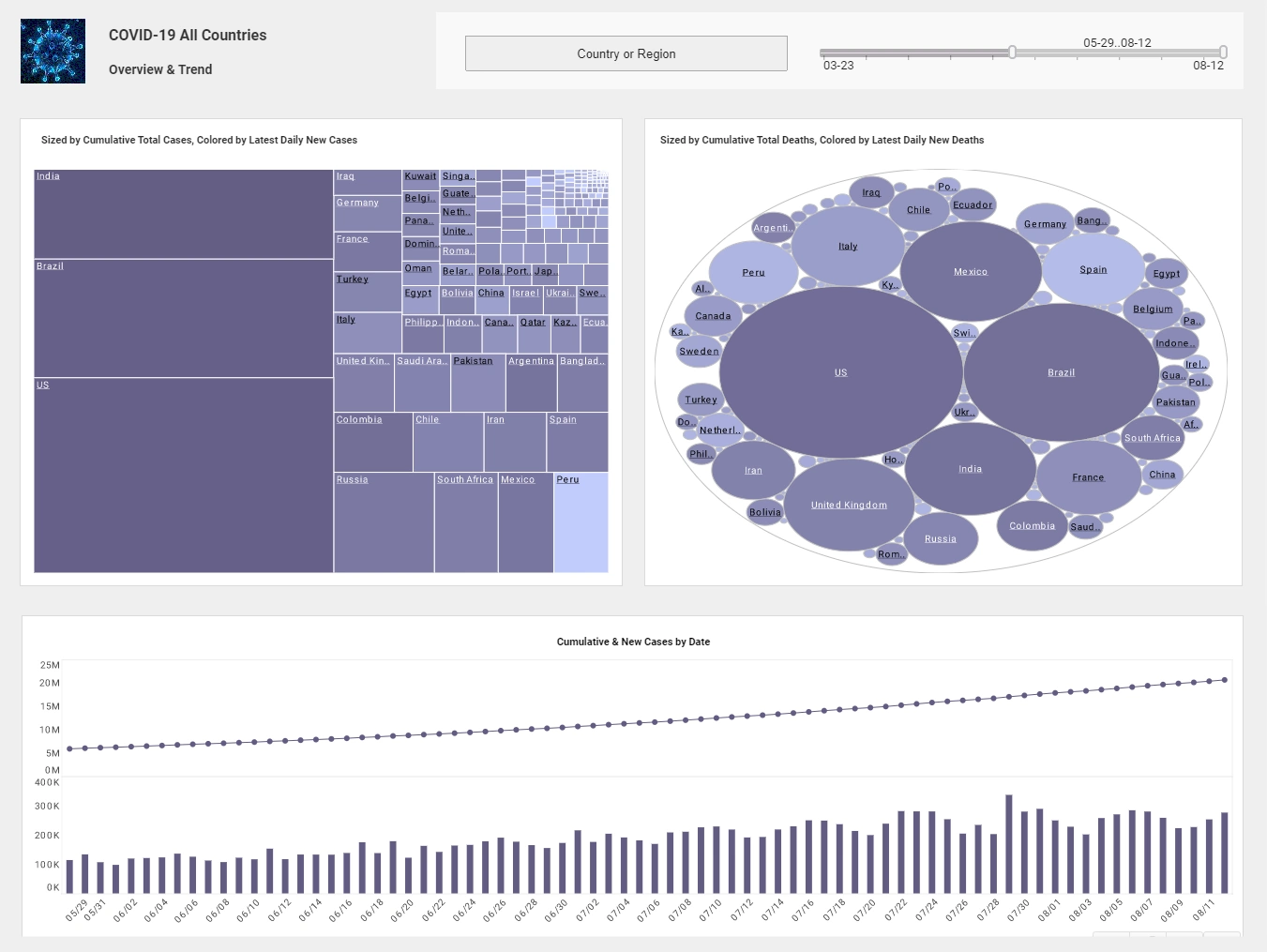
StyleBI also enables advanced analytics for forecasting and predictive modeling, a critical feature for a holographic display manufacturer dealing with emerging technologies and volatile market demand. Historical sales data, customer interest metrics, and industry trends are analyzed to predict future demand for different display models. Time-series forecasting charts display expected sales volumes by region and product type, allowing production planning and resource allocation to align with market expectations. Scenario modeling capabilities simulate the potential impact of supply chain disruptions, competitor actions, or changes in component costs, empowering management to proactively address risks.

Data visualization is a core strength of StyleBI that enhances comprehension across departments. Interactive dashboards allow users to filter by product model, manufacturing site, or time period, making complex datasets accessible to engineers, managers, and executives alike. Heat maps, scatter plots, and bubble charts help uncover correlations between production parameters and product quality or sales performance. Drill-down capabilities enable detailed exploration of underlying data, such as examining a specific production batch or a particular customer segment. This visual and interactive approach ensures that decision-makers can quickly interpret insights and act effectively.
Collaboration across departments is enhanced through StyleBI’s self-service analytics. Engineers, production managers, and marketing teams can access dashboards tailored to their specific needs without requiring extensive technical support. Ad-hoc queries allow employees to explore data and test hypotheses independently, promoting a culture of data-driven decision-making. Role-based access ensures that sensitive information is protected while granting appropriate visibility to relevant users. This democratization of analytics accelerates insight generation and aligns cross-functional teams on shared business objectives.
Real-time analytics and mobile accessibility further extend the platform’s value. Field engineers, sales representatives, and production supervisors can monitor KPIs, receive alerts, and interact with dashboards using tablets or smartphones. Notifications can be configured for key thresholds, such as equipment performance anomalies, high defect rates, or urgent customer requests. This mobility ensures that critical insights are accessible wherever decision-makers are located, supporting responsive and informed actions across the organization.
Finally, the integration of StyleBI into the company’s big data ecosystem has fostered continuous improvement. Data from production, R&D, supply chain, sales, marketing, and finance converge into a single analytics environment, providing a holistic view of organizational performance. The ability to analyze large, heterogeneous datasets allows the manufacturer to identify patterns, optimize processes, and make strategic decisions grounded in data. Over time, this approach improves operational efficiency, product quality, customer satisfaction, and market competitiveness.