The Definition of ETL and Its Advantages and Disadvantages
ETL: Extract, Transform and Load
Today we are focusing on enterprise data integration methods. We will explain extract, transform, and load, better known as ETL technology. You will learn how ETL works, how it's commonly used, as well as advantages and disadvantages of ETL. Our expert for this Webinar is Abhishek Gupta, product manager at InetSoft. Abhishek has experience in business intelligence, data integration, and data management. Now let's hear Abhishek give a tutorial about ETL.
ETL tools, in one form or another, have been around for over 20 years. The first question some people have is what ETL stands for. And that would be extract, transform, and load. Really, the history dates back to mainframe data migration, when people would move data from one application to another. So this is really one of the most mature out of all of the data integration technologies.
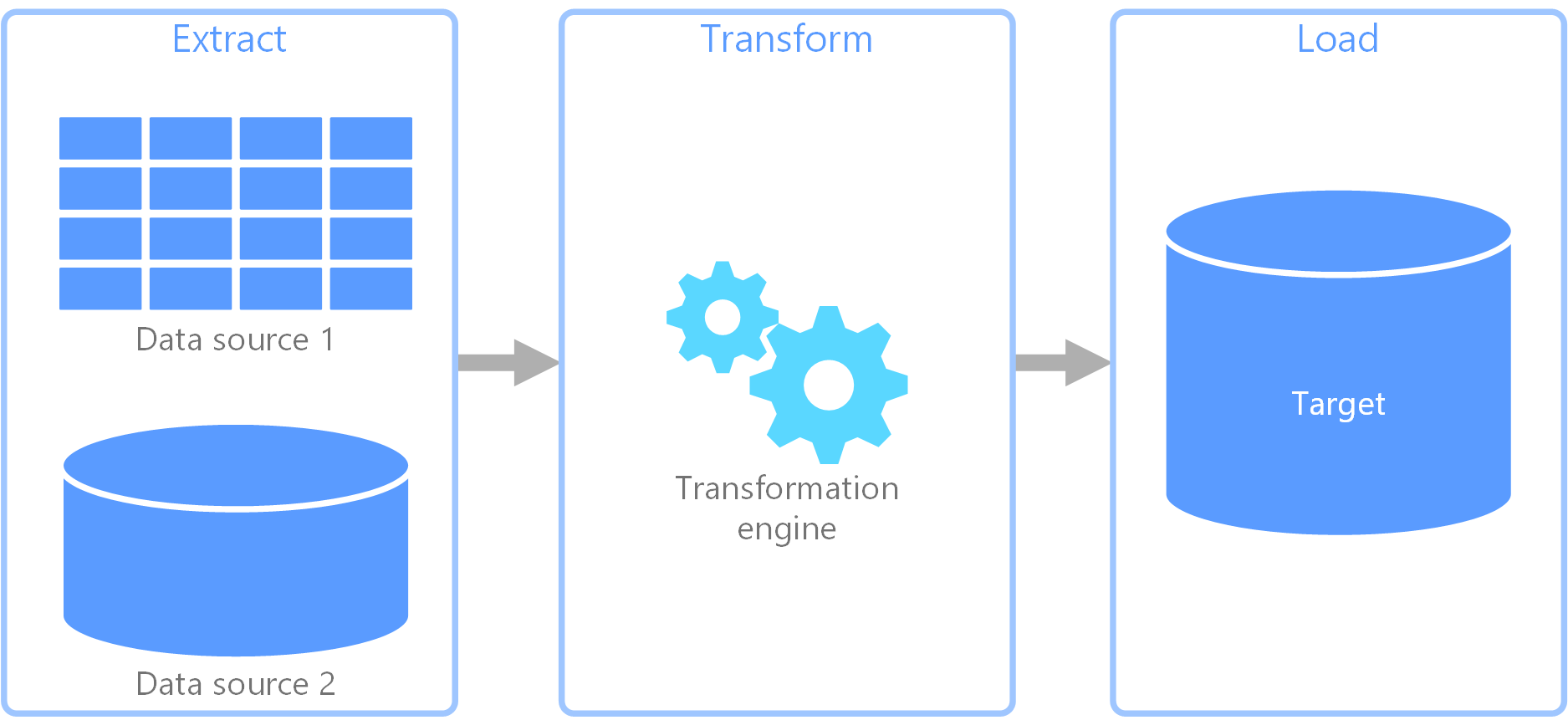
ETL is a data movement technology specifically, where you are getting data from one application's data store and moving it to another location rather than trying to interface to an application's programming interfaces. So you are skipping all of the application's logic, and going right through the data layer. And then, you have a target location where you are trying to land that data. ETL is closely associated with data warehouse because it's most common usage is to load data into a data warehouse for down stream data analytics.
ETL Advantages: Rule Definition vs Coding
The tool itself is used to specify data sources and the rules for extracting and processing that data, and then, it executes the process for you. So it's not really the same thing as programming in a traditional programming sense, where you write procedures and code. Instead, the environment works with a graphical interface where you are specifying rules and possibly using a drag-and-drop interface to show the flows of data in a process.
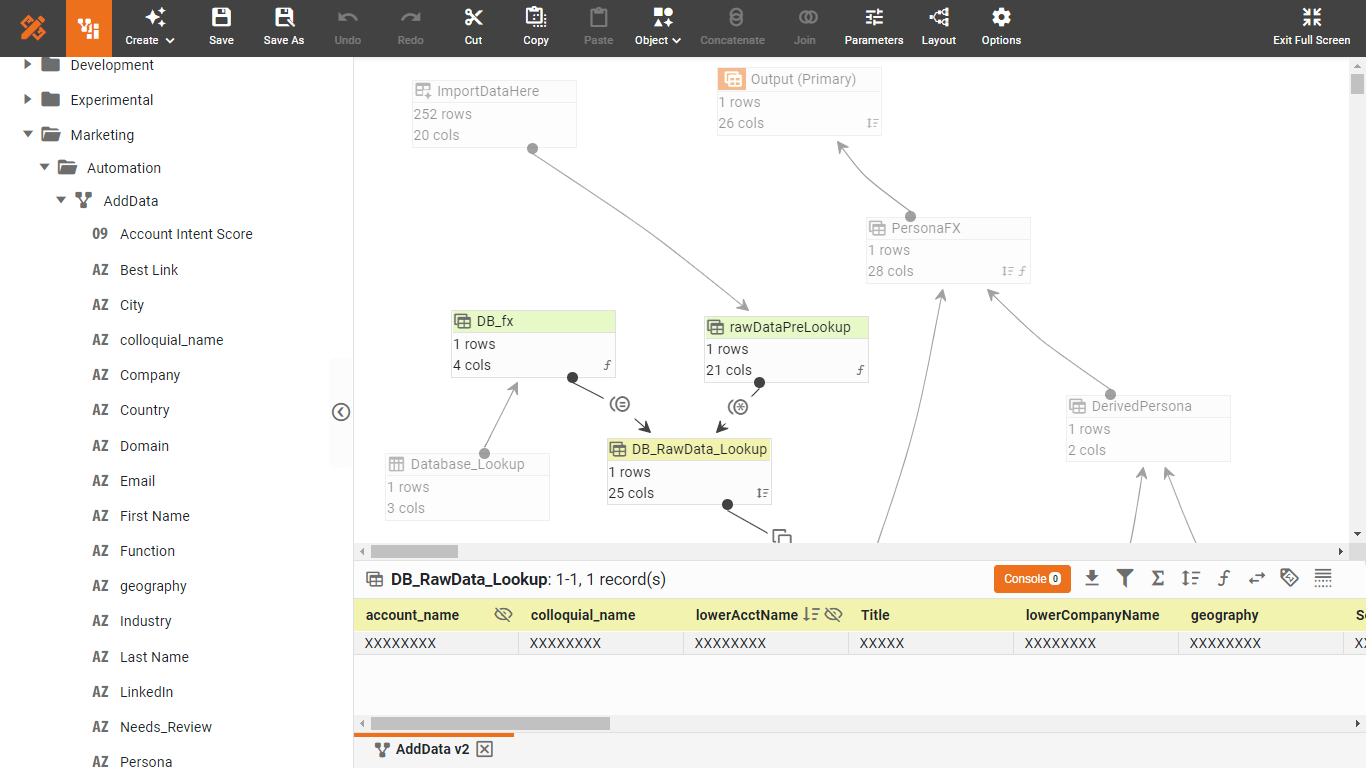
The way it works, in a sense, is that it takes these rules and runs them through an engine or generates code into an executable, which is then executable within your production environment. Most ETL tools are run in a batch mode because that's where they have evolved from. So there is some kind of an event that triggers the extract. Or it's schedule-driven, and the schedule dictates that that at such and such a time, you'll run this particular extract. And then, there can be dependencies in the schedule so that if one thing executes successfully, another thing can be triggered to run.
ETL tools, themselves, are geared towards data oriented developers and DBAs. So these aren't the kind of tools which are really aimed at application developers who are more into procedural coding and third-generation languages. We are looking at somebody who understands data, not necessarily an application programmer, and the preference is, in particular, somebody who understands something about databases and SQL, since about 80% of the time, we are pulling data from databases directly.
So you can read multiple types of databases, files, web services, and bring all of these things together. The way the tools facilitate this is to connect their libraries and integrated metadata stores underneath them. And that makes maintenance and traceability much easier than in a hand-coded environment.
ETL tools are good for bulk data movement, getting large volumes of data, and transferring them in batch. They are good for situations where you have complex rules and transformations. So you have got calculations and string manipulation and data changes and integration of multiple sets of data, and in particular, high volumes of data from different type of sources.

ETL Disadvantages: IT Centric & Static
They do have some weaknesses though. ETL tools, typically, aren't that great at near-real time or on-demand data access. They were geared towards more of a batch mode of working. It should be used for well established, slow changing data transformation for data warehouse. Furthermore, ETL is a IT tool that's not accessible to data analytics and business users directly.
So for most people in the data warehousing environment, in particular, I would say that 80 to 90% of their needs are met with an ETL tool.
ETL tools, themselves, are geared towards data oriented developers and DBAs. So these aren't the kind of tools which are really aimed at data analysts or business power users who need both master data from data warehouse and fast changing, adhoc data. These users typically understand data and some SQL query language, but not necessarily data infrastructure technology like ETL and data warehouses

Agile ETL: Data Mashup
Data Mashup can be viewed as an agile ETL tool for data analysts and power users. Unlike ETL, it doesn’t "load" transformed data into a data warehouse. Instead, it creates a transformation plan that directly serves a particular dashboard or report. The transformation plan is executed at real time therefore most up-to-date data is available.
In cases of complex transformation plan or large data volume, mashup engine can also create high performance local data cache with transformed data. The data cache’s refresh rate can be controlled by users and administrators. In some cases, ETL and data warehouse can be replaced with data mashup. In other cases, users will mash up data from ETL populated Data warehouse with more dynamic data.
Data mashup is normally a integrated part of business intelligence application for visual output design. This facilitaes rapid, iterative development of dashboards and reports.